
Patch Management SLA Template: Critical, High, Medium, Low
A strong patch management SLA template helps organizations answer one question before a vulnerability turns into a bigger problem: how fast are we expected to act? Without that clarity, patching often becomes uneven. One team sees a flaw as urgent, another waits for the next change window, and nobody is completely sure whether the delay is acceptable.
That uncertainty is harder to manage in modern environments. Most organizations are no longer patching only a few internal servers. They are dealing with laptops, cloud workloads, identity systems, business applications, remote access tools, network devices, and internet-facing assets. In many cases, patching responsibility is also shared with suppliers, which is why related processes such as a Third-Party Risk Assessment Checklist 2026 and a Supplier Cybersecurity Contract Template support the same risk model.
A practical SLA brings structure to that complexity. It tells security teams, IT operations, application owners, and leadership what “on time” means for critical, high, medium, and low vulnerabilities. It also defines who owns testing, who approves exceptions, and how overdue items are reported. That is what turns patching from a routine IT task into a measurable control.
Table of Contents
What a Patch Management SLA Template Is
A patch management SLA template is a written document that defines expected timelines, responsibilities, and controls for assessing, testing, approving, deploying, and verifying security patches. In practical terms, it tells the organization how quickly remediation should happen once a patchable issue has been identified and confirmed as relevant.
The document usually applies to multiple asset types. That may include servers, desktops, laptops, cloud workloads, network appliances, security tools, business applications, and public-facing systems. In mature environments, it may also include systems managed partly by third parties, provided patch ownership has been defined contractually.
The best templates do more than list deadlines. They explain how severity is assigned, who owns remediation for each type of asset, what evidence should be retained, and what happens when a patch cannot be applied on time. Patch governance often overlaps with application hardening, vendor security requirements, and identity protection, especially when exposed systems or third-party platforms are involved.

Why a Patch Management SLA Template Matters
A patch management SLA template matters because patch delays rarely happen for only one reason. More often, the delay comes from a mix of operational friction points. The security team identifies a vulnerability. The application owner wants testing first. The infrastructure team already has a full change calendar. The business is worried about downtime. The vendor has not yet confirmed compatibility. In the absence of a clear standard, the issue drifts.
An SLA gives teams a shared operating model before that pressure starts. Security knows what to escalate. IT knows the expected timelines. Application owners know when testing must happen. Leadership can see when an overdue patch stops being a technical backlog item and becomes an accepted business risk.
This is particularly important for exposed services and shared infrastructure. A delayed patch on an internet-facing application, identity service, or remote access platform can quickly become a wider business problem. That is why related hardening work such as an Okta Security Checklist and a Public-Facing Application Security Checklist belongs in the same operational conversation.
For general background, it also helps to understand the broader discipline of vulnerability management and the role of a software patch in reducing known risk.
Patch Management SLA Template by Severity
At the center of any patch management SLA template is the severity model. This is the part of the document that defines how quickly different kinds of vulnerabilities are expected to move through remediation.
Many organizations begin with vendor severity, but mature patching programs usually go further. They also consider exploitability, system exposure, business importance, and whether the affected asset is externally reachable. That broader view matters because a flaw that looks moderate in a test environment may deserve urgent action when it appears on a production-facing system. This is also why many teams use the Common Vulnerability Scoring System as a reference point rather than the only decision factor.
Critical
Critical vulnerabilities require the fastest response. These are typically the issues most likely to create immediate risk, either because exploitation is active, the technical impact is severe, or the affected system is especially sensitive or exposed.
A common SLA target is:
- assess immediately
- confirm applicability as quickly as possible
- patch within 24 to 72 hours
- escalate immediately if the deadline cannot be met
High
High-risk vulnerabilities are serious and still deserve rapid attention, even if they do not always justify the same emergency handling as a critical issue.
A common SLA target is:
- validate within 1 business day
- test through the standard change process
- patch within 7 to 14 days
- document temporary safeguards if delayed
Medium
Medium-risk vulnerabilities are usually handled through planned remediation rather than emergency response. They still require accountability and deadlines, but they can often move through ordinary patch cycles.
A common SLA target is:
- assess during routine triage
- patch within 30 days
- reassess if exploitability or exposure changes
Low
Low-risk vulnerabilities often have narrower business impact or limited exploitability. They should still be tracked, but usually through scheduled maintenance rather than urgent action.
A common SLA target is:
- include in planned maintenance
- patch within 60 to 90 days
- review overdue items during monthly governance

Patch Management SLA Template for Critical, High, Medium, Low
Below is a practical patch management SLA template that can be adapted for internal use.
1. Purpose
This Patch Management SLA defines required timelines, ownership, testing expectations, exception handling, and reporting controls for identifying, evaluating, approving, deploying, and validating security patches across the organization’s environment.
2. Scope
This SLA applies to:
- servers
- endpoints
- laptops and workstations
- cloud workloads
- virtual machines
- network devices
- security appliances
- business applications
- internet-facing systems
- third-party managed systems where patch responsibility is defined
3. Severity Definitions
Severity is assigned using vendor rating, exploit activity, asset exposure, business impact, and operational context.
- Critical: immediate or near-immediate exploitation risk, active exploitation, or severe impact on confidentiality, integrity, or availability
- High: serious vulnerability with meaningful exploitation potential or exposure of important assets
- Medium: moderate risk requiring planned remediation
- Low: lower exploitability or lower business impact
4. Remediation Timelines
Critical: within 72 hours of confirmed applicability
High: within 14 calendar days
Medium: within 30 calendar days
Low: within 90 calendar days
Where active exploitation is confirmed, a system is externally exposed, or a contractual requirement demands faster action, the organization may shorten these timelines.
5. Roles and Responsibilities
Security Team
- monitor vulnerabilities and relevant threat activity
- validate severity and business context
- track remediation status
- escalate overdue critical and high findings
IT Operations
- test and deploy patches
- confirm installation success
- report failed or blocked remediation activity
Application Owners
- support business testing
- assess operational impact
- approve deployment timing where needed
- document dependencies and constraints
Change Management
- support standard and emergency approvals
- maintain change records where required
Leadership and Risk Owners
- review overdue critical issues
- approve temporary exceptions
- monitor repeated SLA failures
6. Testing Requirements
Patches should be tested in staging or pre-production where practical, especially for business-critical systems and shared infrastructure. When the risk of exploitation is unusually high, emergency deployment may move ahead faster than normal testing cycles, but that decision should still be documented.
7. Exceptions and Compensating Controls
If a patch cannot be applied within the required timeline, the system owner must submit a documented exception. The exception should include:
- reason for delay
- affected asset or service
- business impact
- security risk
- temporary safeguards
- target remediation date
- approval from the appropriate owner
Compensating controls may include network restriction, access limitation, additional monitoring, virtual patching, or temporary isolation.
8. Verification and Evidence
After deployment, patch success should be verified through endpoint tools, system management platforms, vulnerability scans, or manual validation where necessary. Evidence should be retained for audit, review, and reporting purposes.
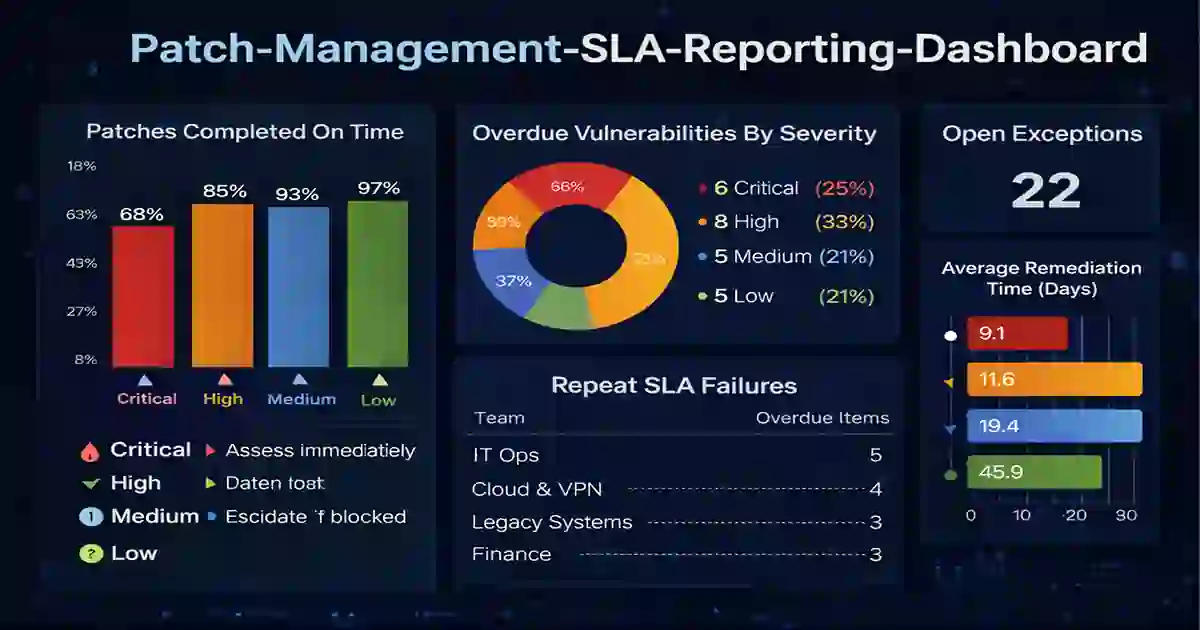
9. Reporting Metrics
The organization should review at least the following metrics each month:
- critical patches completed on time
- high patches completed on time
- overdue vulnerabilities by severity
- number of open exceptions
- repeat SLA breaches by team or asset type
- average remediation time by severity
Patch Management SLA Template for Global Teams
A patch management SLA template becomes more useful when it reflects how organizations actually operate across regions and business units. Global environments rarely move at the same pace. Teams work in different time zones, rely on different vendors, follow different maintenance windows, and support different services.
That does not mean the SLA should become vague. It means the baseline standard should remain clear while the exception process is strong enough to handle real operational differences. In practice, this is what often separates a working patch standard from a policy that exists only for audits.
Asset grouping can help here. Cloud workloads, employee endpoints, exposed production services, internal applications, and legacy platforms rarely move through patching the same way. One SLA can still govern all of them, but the supporting notes should acknowledge the differences.
Global patching standards work best when they account for regional maintenance windows, distributed teams, and long-term technology planning across the environment.
Exceptions, Testing, and Rollback
No patch management SLA template is complete without a clear exception process. Some systems can be patched quickly with very little friction. Others involve vendor dependency, uptime commitments, fragile integrations, or regulated workflows that make rapid deployment more difficult.
That is why an exception should never be treated as an informal delay. It should be a governed decision with clear ownership, compensating controls, and a defined target date. Otherwise, patch postponement becomes normalized without being managed properly.
Rollback planning matters for the same reason. Critical systems should have a basic recovery path if a patch causes instability. This is especially important for identity services, shared infrastructure, remote access platforms, and exposed applications. Identity platforms often sit high on remediation priorities because outages or compromise there can affect the wider environment.
Reporting and Governance
A patch management SLA template is only useful if the organization can show whether it is being followed. Monthly dashboards, aging reports, overdue critical escalation, repeat exception tracking, and asset-group comparisons help turn the SLA into a living control rather than a static document.
Reporting also reveals where operational friction actually sits. One team may miss deadlines because of vendor dependency. Another may struggle with testing bottlenecks. A third may carry large numbers of overdue findings on older systems that need replacement rather than repeated exception approval.
Patch reporting also supports broader resilience goals by showing whether deadlines are being met, where exceptions are growing, and which teams or systems are repeatedly falling behind. It also fits well with the broader idea of a service-level agreement, since the goal is not just to write a standard but to measure it.
Common Mistakes to Avoid
One common mistake is setting deadlines that sound strong but are not realistically achievable. If the SLA cannot be met in normal operations, teams will gradually stop treating it as a real standard.
Another mistake is relying only on vendor severity. In real environments, exposure and business context matter just as much. A medium-rated flaw on an internet-facing production asset may deserve faster treatment than a higher-rated issue on a low-value internal test system.
A third mistake is failing to document exceptions properly. Once overdue remediation becomes routine and undocumented, governance weakens quickly. A final mistake is treating patching as a purely technical function when it is really a shared risk management process involving security, operations, business ownership, and leadership.
Final Takeaway
A well-designed patch management SLA template gives teams a practical structure for handling critical, high, medium, and low vulnerabilities. It defines who is responsible, how quickly action is expected, how exceptions are approved, and how performance is measured.
The best templates are clear enough to guide action and realistic enough to be followed. They do not remove complexity, but they make complexity easier to manage. When patching expectations are written well, teams move faster, accountability improves, and security decisions become easier to explain.

